


在大型語言模型(LLM)的推論速度競賽中,單純堆砌 GPU 算力已不再是唯一的致勝關鍵,真正的戰場早已轉移至「記憶體頻寬(Memory Bandwidth)」的調度效率。KV Cache(鍵值快取)與 Prefetching(預取技術) 正是這場效能革命的核心,它們不僅是技術名詞,更是現代生成式 AI 能夠在毫秒級回應使用者需求的底層支柱。KV Cache 通過「以空間換取時間」的策略,避免了神經網路在生成每一個 Token 時重複計算歷史訊息;而 Prefetching 則如同精密的物流系統,在運算單元閒置之前,提前將數據搬運至高速快取中。這兩者的結合,定義了當代 AI 推論引擎(Inference Engine)的極限效能。
KV Cache:Transformer 架構下的「記憶體」
要理解 KV Cache,必須先回到 Transformer 架構的本質。在生成式 AI 的推論過程中,模型是「自回歸(Autoregressive)」的,這意味著每生成一個新的字(Token),都需要回顧之前所有的輸入與已生成的內容。如果沒有快取機制,模型每生成第 N 個字,就需要重新計算前 N-1 個字的所有 Attention 機制中的 Key(鍵)與 Value(值)矩陣。
KV Cache 的核心價值在於消除冗餘計算。它將之前步驟計算好的 Key 和 Value 矩陣儲存在 GPU 的顯式記憶體(VRAM)中。當模型生成下一個 Token 時,只需計算當前新 Token 的 Query、Key 和 Value,並從快取中讀取歷史紀錄進行矩陣運算。這項技術讓推論的時間複雜度從原本隨著序列長度呈平方增長,大幅降低至線性增長,是 ChatGPT、Claude 等模型能夠進行長對話的物理基礎。
Prefetching:打破記憶體牆的策略
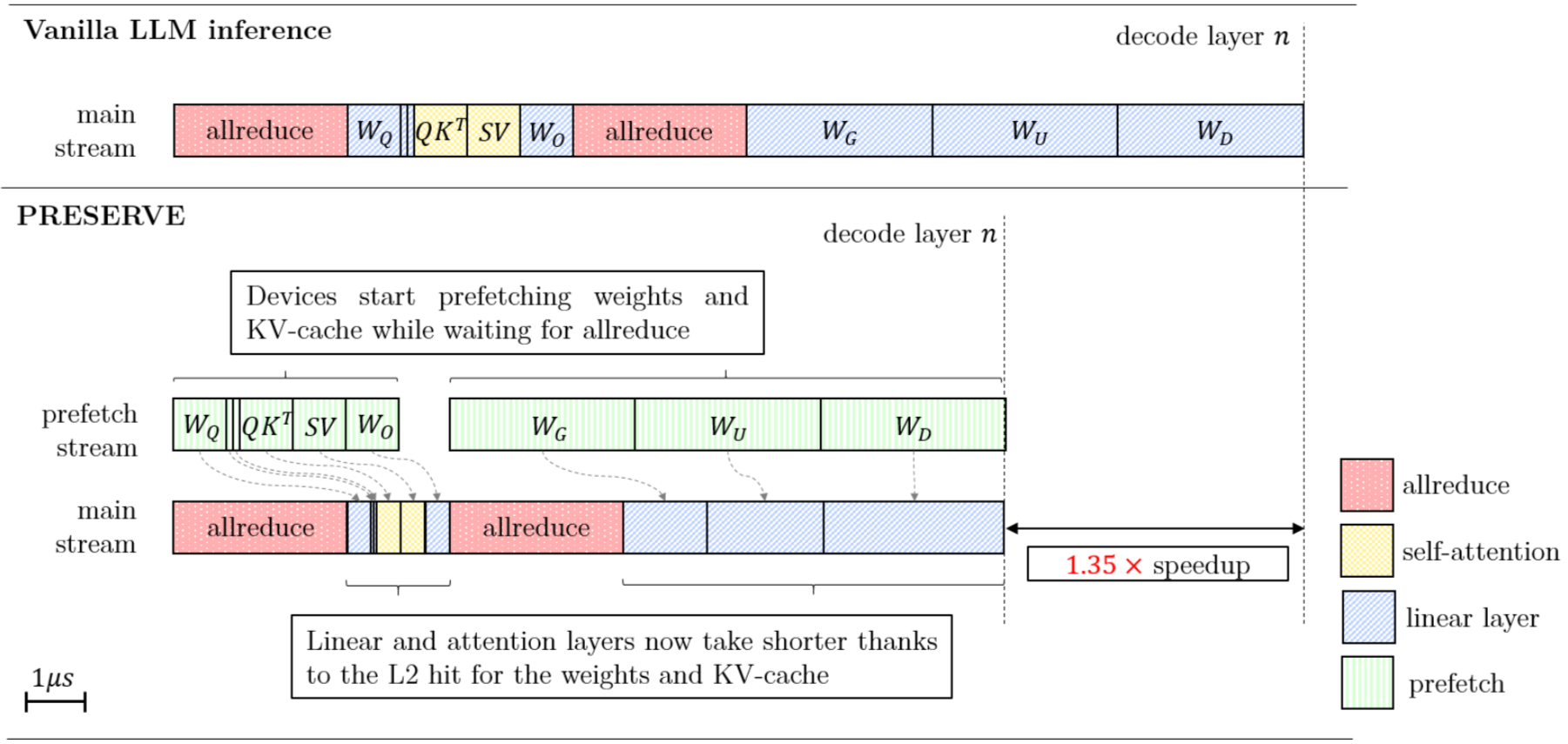
雖然 KV Cache 解決了重複計算的問題,但它引入了新的挑戰:龐大的記憶體佔用與讀取延遲。隨著對話長度增加,KV Cache 的體積會迅速膨脹,導致 GPU 的高頻寬記憶體(HBM)與運算單元(SRAM/Registers)之間的數據傳輸成為瓶頸,這就是著名的「記憶體牆(Memory Wall)」問題。
Prefetching(預取技術) 便是為了解決此瓶頸而生。它的運作原理類似於 CPU 的快取預取,但在 GPU 上更為複雜且針對性強:
- 隱藏延遲(Latency Hiding):當 GPU 的計算單元(Tensor Cores)正在處理當前的矩陣乘法時,Prefetching 機制會並行地向 HBM 發出指令,將預計下一階段需要的 KV Cache 數據提前拉入 L1 或 L2 快取中。
- 管線化優化(Pipelining):透過軟體流水線技術,讓「數據搬運」與「數據計算」在時間軸上重疊。理想狀態下,計算單元永遠不需要「等待」數據到位,從而最大化硬體的利用率(Utilization)。
技術生態與不可替代性
在目前的 AI 技術堆疊中,KV Cache 管理與 Prefetching 優化已成為 vLLM、TensorRT-LLM 等高效推論框架的護城河。
- PagedAttention 的興起:受到作業系統虛擬記憶體管理的啟發,新一代的技術將 KV Cache 分割成不連續的區塊(Blocks),解決了傳統連續記憶體分配帶來的碎片化問題,這本質上也是為了更有效地配合 Prefetching 機制進行數據調度。
- 硬體層面的支援:NVIDIA 最新的 Hopper 架構(H100)引入了更強大的 Tensor Memory Accelerator (TMA),從硬體層面加速了異步記憶體複製(Asynchronous Copy),這正是為了讓 Prefetching 能夠更極致地發揮作用。
繁榮背後的代價:無限上下文的物理極限
儘管 KV Cache 與 Prefetching 大幅提升了 LLM 的可用性,但我們必須正視這項技術路徑背後的隱憂:記憶體消耗的線性爆炸。
隨著業界追求「無限上下文(Infinite Context)」,例如 1M 甚至 10M Token 的輸入視窗,KV Cache 的大小將會增長到單張甚至單台伺服器 GPU 無法承載的地步。目前的主流解法如 Grouped-Query Attention (GQA) 雖然減少了 KV Cache 的儲存需求,或者利用 Quantization (量化) 壓縮快取,但這些都只是延緩了極限的到來,而非徹底解決問題。
這種對顯存容量的極度依賴,導致 AI 產業的硬體成本居高不下,更加劇了算力壟斷的局面。未來的技術突破點,或許不在於如何更優雅地「快取」這些數據,而在於是否能發明一種不需要完整歷史 KV 矩陣也能保持上下文連貫性的全新架構(例如 State Space Models, SSMs),徹底顛覆現有的 Transformer 範式。在那個轉折點到來之前,KV Cache 與 Prefetching 仍將是支撐 AI 智慧的基石,也是每一位 AI 工程師必須跨越的技術門檻。
Q: 什麼是 KV Cache?為什麼 LLM 需要它?
A: KV Cache(鍵值快取)是一種在大型語言模型推論過程中使用的技術。由於 LLM 是逐字生成的,為了避免每生成一個新字都要重新計算前面所有字的 Attention 參數,系統會將計算過的 Key 和 Value 矩陣儲存起來。這能大幅減少重複運算,顯著提升生成速度並降低延遲。
Q: Prefetching 在 AI 推論中扮演什麼角色?
A: Prefetching(預取)是一種記憶體優化技術。由於 GPU 的計算速度遠快於從記憶體讀取數據的速度,Prefetching 會在計算單元處理當前任務時,預先將下一步需要的數據從慢速記憶體(HBM)搬運到快速快取(SRAM)中,從而「隱藏」讀取延遲,確保計算單元不會因為等待數據而閒置。
Q: KV Cache 的主要缺點是什麼?
A: KV Cache 的主要缺點是極度消耗顯示卡記憶體(VRAM)。隨著對話長度(Context Window)增加,儲存 KV Cache 所需的記憶體會線性增長。這導致在長文本應用中,記憶體容量往往比算力更早成為瓶頸,限制了模型能處理的資訊量或並發使用者數量。
Q: KV Cache 與傳統的 CPU 快取有什麼不同?
A: 傳統 CPU 快取(L1/L2/L3)是硬體層面的通用數據暫存機制,對程式設計師通常是透明的。而 LLM 中的 KV Cache 是應用層面的特定數據結構(Tensor),需要軟體明確地管理、分配與讀寫。雖然兩者概念相似(都是為了加速存取),但 KV Cache 是針對 Transformer 架構特化的產物。
{"@context":"https://schema.org","@type":"TechArticle","headline":"揭開 LLM 極速推論的秘密:KV Cache 與 Prefetching 如何突破 AI 算力瓶頸?","description":"深入解析大型語言模型(LLM)推論加速的關鍵技術:KV Cache 與 Prefetching。本文剖析其底層運作原理、如何突破記憶體頻寬瓶頸(Memory Wall),以及這項技術背後對 AI 硬體成本與無限上下文發展的深層影響。","author":{"@type":"Organization","name":"AI Tech Insights TW"},"datePublished":"2025-12-29","keywords":["KV Cache","Prefetching","LLM Optimization","Memory Bandwidth","AI Inference","HBM","Transformer Architecture"]}



發表迴響