算力經濟
-

OpenAI Pro 100 美元訂閱解析:Codex、算力額度與 AI 編程成本
OpenAI Pro 100 美元訂閱方案與 Codex 使…
-

算力階級論:靠 AI IDE 與多 Agent 協作終結 Token 焦慮
別再盯著 Token 進度條發愁!這篇文章直擊開發者痛點,教…
-

OpenAI 算力配給解析:AI 訂閱成本、模型額度與備援策略
OpenAI 算力配給反映 AI 訂閱制、模型額度與推理成本…
-

MiniMax M2.5 解析:低成本 AI Agent、模型能力與智能經濟學
MiniMax M2.5 主打低成本高效能模型能力,適合用來…
-

無限 Context Window 是騙局?TTT-E2E 如何拯救 LLM 算力地獄
別再相信無限 Context 的行銷話術!Transform…
-

AGI-Next 2026 峰會整理:AI Agent、B2B 應用與中國 AI 產業趨勢
AGI-Next 2026 峰會聚焦 AI 產業從聊天模型走…
-

突破 LLM 長文本瓶頸:預測性 KV Cache 換入換出如何重塑推論效能?
深入解析預測性 KV Cache 換入換出 (Specula…
-

超越 GQA 的推理革命:DeepSeek 如何用 MLA 重新定義 LLM 的記憶體極限?
深入解析 DeepSeek 核心技術 Multi-head …
-

FP8 / FP4 Microscaling 解析:Blackwell、模型壓縮與 AI 推理效率
FP8 / FP4 Microscaling 可用來理解新一…
-
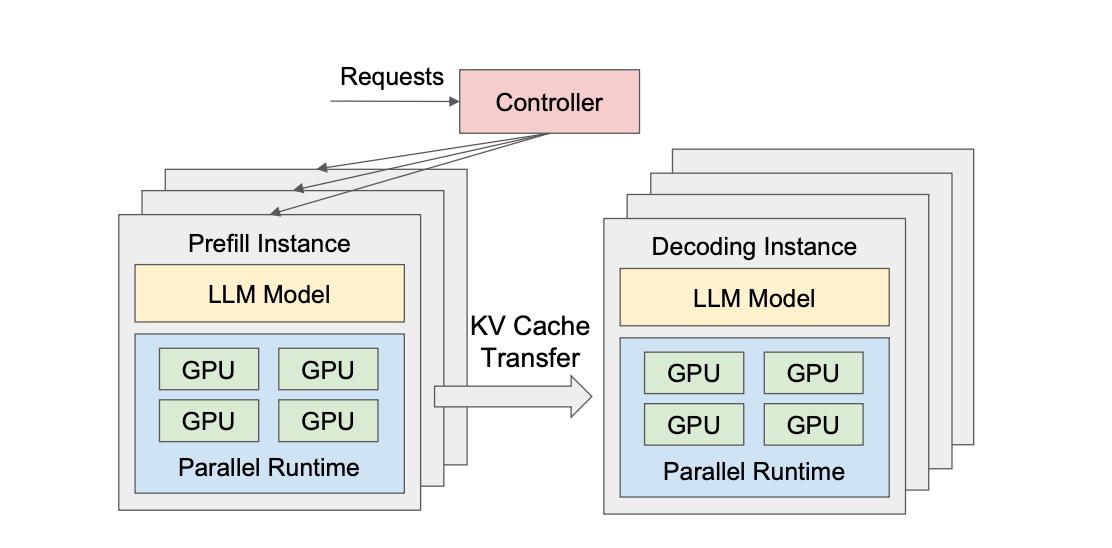
DistServe 架構解密:KV Cache 跨節點傳輸協議如何突破 LLM 推論瓶頸?
深入解析 DistServe 技術架構,探討其創新的 KV …
-

算力效能的終極解放:動態精度切換與 Bit-level Scalability 如何重塑 AI 晶片架構?
深入解析動態精度切換(Bit-level Scalabili…
-
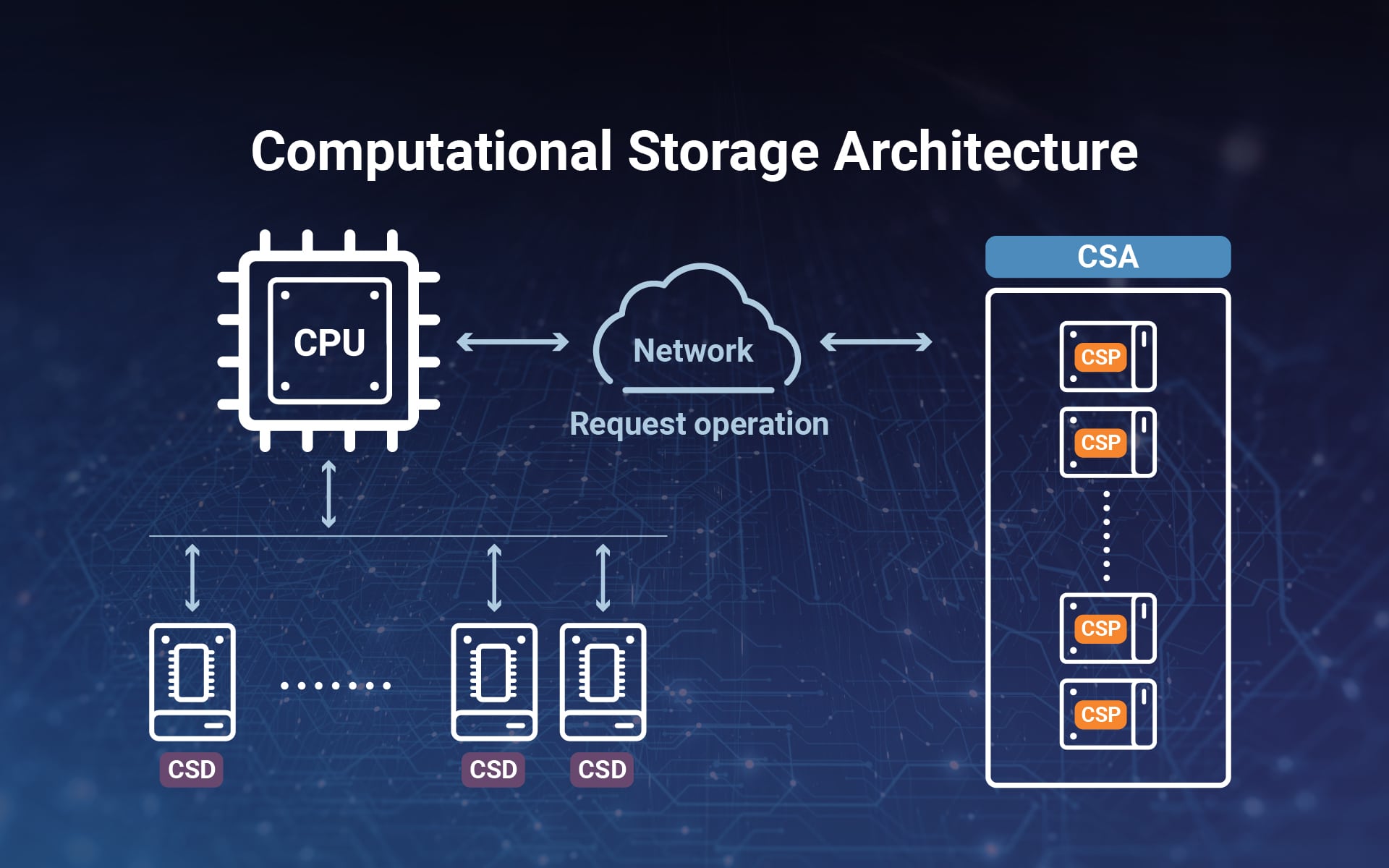
數據不再搬家?打破馮諾依曼瓶頸的終極方案:計算儲存一體 Computational Storage 深度解析
computational-storage-near-dat…
-

告別 PCIe 瓶頸:跨行程共享顯存 IPC Shared GPU Memory 的底層邏輯與效能革命
還在忍受 GPU 到 CPU 的龜速搬運?本文拆解跨行程共享…
-

不再被 VRAM 綁架!揭秘 Shared-Memory KV Cache 如何讓 LLM 推論速度翻倍
深入解析 Shared-Memory KV Cache 技術…
-

解鎖 AI 算力極限:NVIDIA TensorRT-LLM 如何讓大模型推論速度提升 8 倍?
深入解析 NVIDIA TensorRT-LLM:這項技術如…
-

SGLang 推理優化全攻略:深入 Interpreter 層實現結構化生成與 KV Cache 重用
還在被大模型的格式幻覺與推理延遲折磨?SGLang Inte…
-
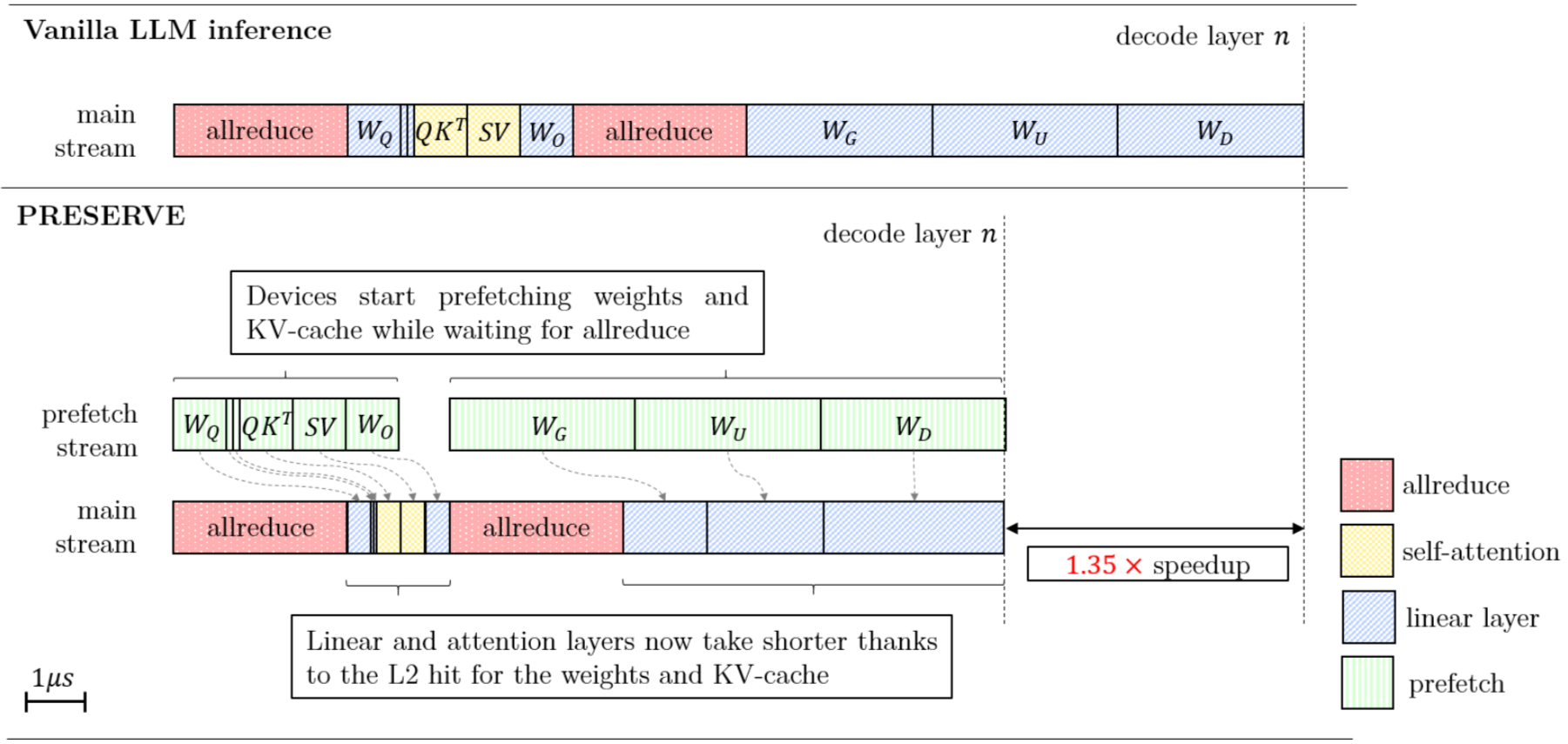
揭開 LLM 極速推論的秘密:KV Cache 與 Prefetching 如何突破 AI 算力瓶頸?
深入解析大型語言模型(LLM)推論加速的關鍵技術:KV Ca…
-

DeepSeek-V3 效能解密:DeepEP 通訊庫如何重塑 MoE 模型的訓練極限?
深入解析 DeepSeek-V3 的核心通訊庫 DeepEP…


